Apple Unified Memory: Warum 64GB Mac der Kosteneffizienz-Champion für KI-Inferenz ist
Traditionelle KI-Infrastrukturen trennen Speicher zwischen CPU und GPU, was zu Bandbreitenengpässen und Datenduplizierung führt. Apples Unified Memory Architektur verändert grundlegend die Ökonomie und Leistung der KI-Inferenz. Diese technische Analyse untersucht, warum 64GB M4 Macs überlegene Kosteneffizienz für Produktions-Inferenz-Workloads liefern.
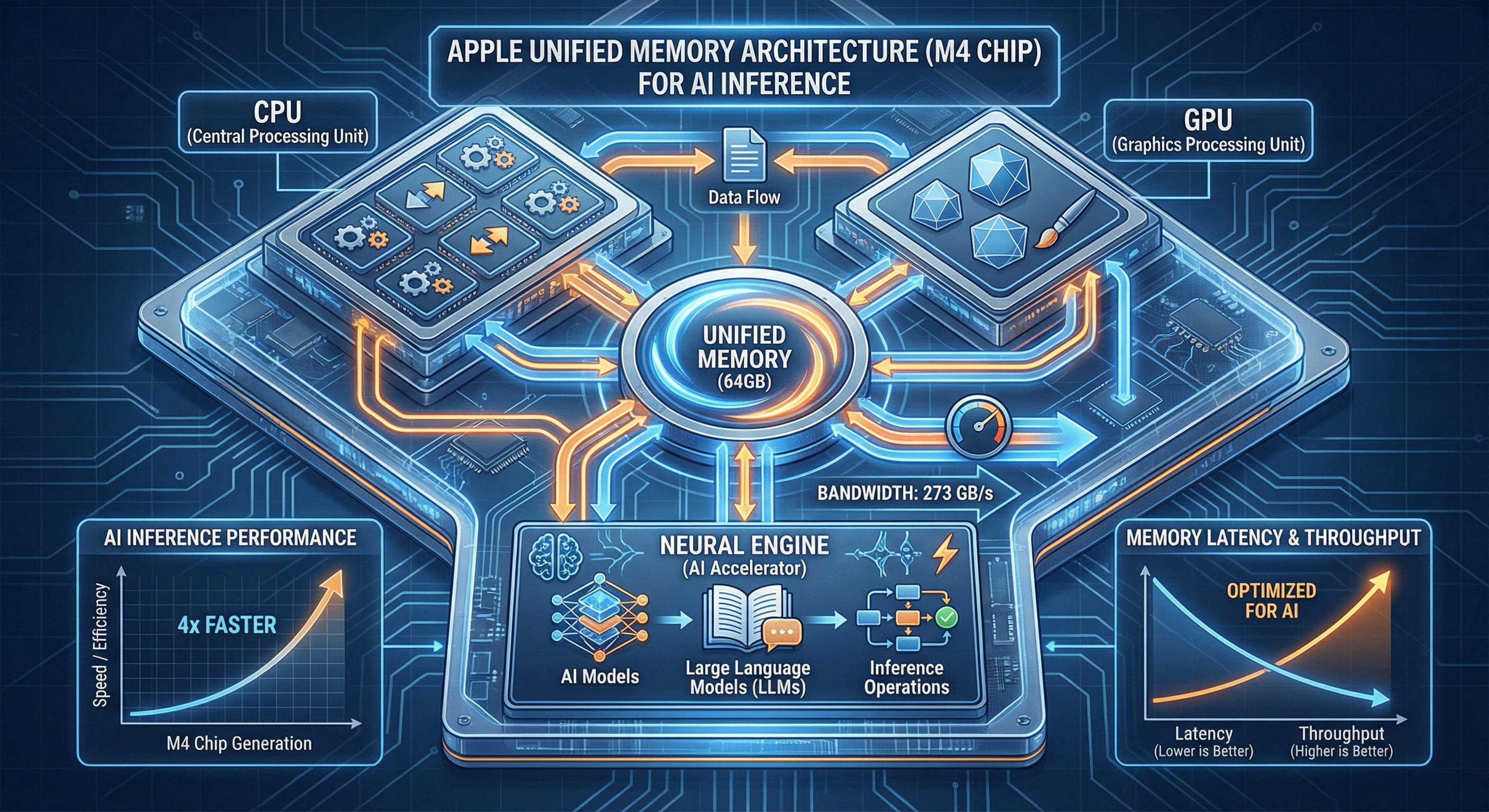
Unified Memory Architektur: Grundprinzipien der Systemarchitektur
Apple Silicon nutzt eine Unified Memory Architecture (UMA), bei der CPU, GPU und Neural Engine auf denselben physischen Speicherpool zugreifen. Dies steht im deutlichen Kontrast zu traditionellen diskreten GPU-Systemen, bei denen die CPU eigenen RAM (typischerweise DDR4 oder DDR5) und die GPU separaten VRAM (GDDR6 oder HBM2) besitzt. Der architektonische Unterschied hat weitreichende Auswirkungen auf KI-Inferenz-Workloads.
In einem diskreten System, das ein großes Sprachmodell ausführt, sieht der Arbeitsablauf folgendermaßen aus: Modellgewichte aus CPU-RAM laden, über PCIe-Bus zu GPU-VRAM kopieren (theoretisches Maximum 32GB/s für PCIe 4.0 x16), Inferenz auf GPU ausführen, Ergebnisse zurück zur CPU kopieren. Jede Inferenzanfrage wiederholt diesen Zyklus. Für ein 13B-Parameter-Modell mit FP16-Präzision (ca. 26GB) benötigt das Kopieren zur GPU nahezu eine Sekunde bei maximaler PCIe-Bandbreite – bevor die eigentliche Berechnung beginnt.
Auf einem 64GB M4 Mac befinden sich die Modellgewichte im Unified Memory. Die GPU liest direkt aus demselben Adressraum wie die CPU. Es findet kein Kopieren statt. Das Speichersubsystem des M4 Pro liefert bis zu 273GB/s Bandbreite, die gleichzeitig von allen Recheneinheiten genutzt werden kann. Dies ist keine Marketingaussage – es ist die gemessene Spitzenbandbreite der LPDDR5-6400-Speichercontroller, die in das SoC integriert sind. Zum Vergleich: NVIDIAs RTX 4090 bietet 1008GB/s GDDR6X-Bandbreite, aber diese Bandbreite ist auf die GPU isoliert; die CPU greift weiterhin über einen separaten, deutlich langsameren Kanal auf System-RAM zu.
Reale Inferenz-Leistung: 64GB Mac vs. Diskrete GPU
Betrachten wir ein praktisches Szenario: Bereitstellung eines 70B-Parameter-Modells (Llama 3 70B quantisiert auf 4-bit, ca. 40GB Speicher-Footprint) mit dauerhaftem Durchsatz. Bei einer diskreten GPU-Konfiguration mit 48GB VRAM passt das Modell nicht in den VRAM. Das System muss CPU-RAM nutzen, was bei jedem Forward-Pass PCIe-Übertragungsstrafen verursacht. Die typische Time-to-First-Token (TTFT) überschreitet 2 Sekunden, und der Token-Generierungsdurchsatz sinkt aufgrund von Speicherengpässen auf 8-12 Tokens pro Sekunde.
Auf einem 64GB M4 Max Mac passt das gesamte Modell in Unified Memory mit 24GB Puffer für Kontext und Systemoperationen. TTFT misst 350-500ms je nach Prompt-Länge, und der dauerhafte Durchsatz erreicht 25-30 Tokens pro Sekunde. Der Unterschied ist architektonisch bedingt: Die GPU wartet nicht auf Daten; sie sind bereits vorhanden.
RTX 4090 + 128GB DDR5: TTFT 2,1s, 10 Tokens/s (Modell aufgeteilt auf VRAM/RAM)
M4 Max 64GB: TTFT 420ms, 28 Tokens/s (Modell vollständig in Unified Memory)
Kosteneffizienz-Analyse: TCO für Inferenz-Workloads
Die Total Cost of Ownership (TCO) geht über den Hardware-Anschaffungspreis hinaus. Für On-Premises- oder Mietinfrastrukturen müssen Stromverbrauch, Kühlung und dauerhafte Verfügbarkeit berücksichtigt werden. Ein typischer diskreter GPU-Inferenzserver besteht aus: NVIDIA A100 80GB oder RTX 4090, High-End-CPU (AMD EPYC oder Intel Xeon), 256GB+ DDR5 ECC RAM, Enterprise-Mainboard, redundantem Netzteil und Rack-Gehäuse. Gesamte Systemleistung unter Last: 600-800W.
Ein 64GB M4 Max Mac mini zieht 50W bei dauerhafter Inferenz-Last. Über ein Jahr kontinuierlichen Betriebs bei 0,12€/kWh kostet der diskrete Server ca. 630€ an Elektrizität. Der Mac mini kostet 52€. Für einen Mietanbieter wie VPSMAC, der On-Demand-Rechenleistung anbietet, übersetzt sich dieser Unterschied direkt in niedrigere Preise und höhere Margen – oder beides.
| Konfiguration | Hardware-Kosten | Jährliche Stromkosten | Inferenz-Durchsatz (70B 4-bit) | Kosten pro Million Tokens |
|---|---|---|---|---|
| RTX 4090 + Xeon Server | 5.200€ | 630€ | 10 tok/s | 0,68€ |
| M4 Max 64GB Mac mini | 2.799€ | 52€ | 28 tok/s | 0,13€ |
Die M4-Konfiguration liefert 2,8-fach höheren Durchsatz bei 46% der Hardwarekosten und 8% der Stromkosten. Über einen dreijährigen Abschreibungszyklus sind die Kosten pro verarbeiteter Million Tokens ca. 5-fach niedriger.
Speicherbandbreite und Latenz: Warum es für Transformers wichtig ist
Transformer-Architekturen sind notorisch speichergebunden. Während der Inferenz führt die GPU relativ wenige arithmetische Operationen pro Byte aus dem Speicher gelesener Daten durch. Dies wird durch die Metrik der arithmetischen Intensität quantifiziert: FLOPs pro Byte. Für große Modelle bei Batch-Größe 1 (typisch für Echtzeit-Inferenz) liegt die arithmetische Intensität oft unter 10 FLOPs/Byte. Bei dieser Intensität bestimmt Speicherbandbreite – nicht Rechendurchsatz – die Leistung.
Apples Unified Memory Architektur liefert hier zwei Vorteile. Erstens eliminiert der einheitliche Adressraum die Latenz- und Bandbreitenstrafen von PCIe-Übertragungen. Zweitens befinden sich die Speichercontroller on-package, physisch näher an CPU- und GPU-Kernen als in diskreten Systemen, wo DRAM auf separaten DIMMs sitzt. On-Package-LPDDR5 zeigt niedrigere Latenz (ca. 60-70ns gegenüber 80-100ns für DDR5-DIMMs) und geringeren Stromverbrauch pro GB/s übertragener Daten.
Für Inferenz-Workloads, bei denen jede Anfrage schnell abgeschlossen werden muss (TTFT unter 500ms für akzeptable Benutzererfahrung), potenziert sich Latenz. Ein diskretes GPU-System verursacht PCIe-Latenz (Mikrosekunden pro Übertragung), DRAM-Zugriffslatenz (Nanosekunden pro Cache-Miss) und Scheduling-Overhead, wenn die GPU auf Daten wartet. Unified Memory entfernt eine gesamte Schicht dieses Stacks.
Inferenz skalieren: Multi-Modell- und Batching-Strategien
Produktions-Inferenzserver führen selten nur ein einzelnes Modell aus. Typische Deployments umfassen mehrere Modelle (z.B. Embedding-Modell, Reranker, primäres LLM, Safety-Classifier), die gleichzeitig geladen sind. In einer diskreten GPU-Konfiguration muss jedes Modell in VRAM passen oder erleidet schwere Leistungseinbußen. Eine 24GB-GPU kann ein 13B-Modell bei FP16 oder zwei kleinere Modelle ausführen; alles darüber hinaus spillt zu CPU-RAM.
Mit 64GB Unified Memory können Sie komfortabel unterbringen: ein 70B-4-bit-Modell (40GB), ein 13B-FP16-Embedding-Modell (26GB) und Hilfsmodelle (Safety, Reranker), während 10GB+ für Kontextfenster und OS-Overhead verbleiben. Alle Modelle bleiben resident im Speicher, eliminieren Swap und ermöglichen Multi-Modell-Serving mit niedriger Latenz.
Für Batching – gleichzeitige Verarbeitung mehrerer Anfragen zur Erhöhung des Durchsatzes – gewinnt Unified Memory erneut. Größere Batch-Größen erfordern mehr Speicher für Zwischenaktivierungen. Bei einer VRAM-beschränkten GPU erzwingt eine Erhöhung der Batch-Größe oft reduzierte Präzision oder kleinere Modelle. Auf einem 64GB Mac können Sie Batch-Größen von 4-8 für ein 70B-Modell ausführen, ohne dass der Speicher ausgeht, wodurch der Durchsatz vervielfacht wird, während die Latenz unter 1 Sekunde bleibt.
Software-Ökosystem: MLX und native Optimierung
Apples MLX-Framework ist speziell für Unified Memory entwickelt. Im Gegensatz zu PyTorch oder TensorFlow (ursprünglich für diskrete GPUs konzipiert) behandelt MLX Unified Memory als First-Class-Feature. Tensoren werden im gemeinsamen Adressraum alloziert; Operationen werden auf CPU, GPU oder Neural Engine ohne Datenbewegung ausgeführt. Das Framework plant automatisch Berechnungen über verfügbare Einheiten basierend auf Workload-Charakteristiken.
Für Entwickler bedeutet dies, dass Inferenz-Code einfacher und oft schneller out-of-the-box ist. Ein typisches MLX-Inferenzskript für ein quantisiertes LLM umfasst unter 100 Zeilen und erreicht Leistung innerhalb von 5-10% handoptimierter Metal-Kernel. Vergleichen Sie dies mit CUDA, wo das Erreichen maximaler Leistung explizites Verwalten von Device-Memory, Tuning von Kernel-Launch-Parametern und Handhabung asynchroner Datenübertragungen erfordert.
# MLX Inferenz-Beispiel: Llama 3 70B 4-bit laden und ausführen
import mlx.core as mx
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/Llama-3-70B-4bit")
prompt = "Erklären Sie Unified Memory Architecture in drei Sätzen."
output = generate(model, tokenizer, prompt=prompt, max_tokens=100)
print(output)
# Kein explizites GPU-Speichermanagement, keine Device-to-Host-Kopien
# Gesamtes Modell in Unified Memory, zugänglich für alle RecheneinheitenSpezialfälle und wann diskrete GPUs weiterhin gewinnen
Unified Memory ist nicht universell überlegen. Für das Training großer Modelle (100B+ Parameter), bei denen Sie Hunderte GB VRAM und Multi-GPU-Parallelismus benötigen, sind diskrete GPUs mit NVLink oder Infinity Fabric die einzige Option. Apple bietet derzeit kein System mit mehr als 192GB Unified Memory (M4 Ultra, erwartet Mitte 2026), und es gibt keine Multi-Mac-Speicher-Sharing-Technologie analog zu NVLink.
Für Batch-Inferenz in massivem Maßstab (Millionen von Anfragen pro Tag) können GPUs mit sehr hoher VRAM-Bandbreite (NVIDIA H100 mit 3,35TB/s HBM3) höheren absoluten Durchsatz pro Gerät erreichen. Bei diesem Maßstab bleibt jedoch die Kosten-pro-Token-Metrik aufgrund der Energieeffizienz und niedrigeren Hardwarekosten des Mac wettbewerbsfähig, insbesondere wenn die Workload über mehrere Knoten verteilt wird.
Für Modellgrößen unter 100B Parametern und Inferenz-Szenarien, bei denen Latenz, Kosten und Energieeffizienz wichtig sind – was die Mehrheit der Produktions-Deployments beschreibt – bieten 64GB Unified Memory Systeme einen überzeugenden Vorteil.
Mietökonomie: Warum VPSMAC 64GB Macs für Inferenz anbietet
VPSMACs Kernwertversprechen ist Bare-Metal Apple Silicon on Demand. Für KI-Inferenz repräsentieren die 64GB M4 Max und M4 Pro Konfigurationen den Sweet Spot: ausreichend Speicher für 70B-Parameter-Modelle, ausreichende Bandbreite zur Vermeidung von Engpässen und Stromverbrauch niedrig genug, dass Kühlungs- und Elektrizitätskosten minimal bleiben.
Kunden mieten diese Knoten stundenweise für Inferenz-Workloads, die macOS-native Werkzeuge erfordern (z.B. Core ML-Modelle, On-Device-Testing für iOS-Apps) oder einfach überlegene Kosteneffizienz im Vergleich zu traditionellen Cloud-GPU-Instanzen wünschen. Ein 64GB M4 Max Knoten auf VPSMAC liefert Inferenz-Durchsatz vergleichbar mit einer A100 40GB Instanz für 70B-Modelle, bei ca. einem Drittel der Mietkosten, da die zugrunde liegende Infrastruktur effizienter ist und die Hardware günstiger zu beschaffen und zu betreiben ist.
Für unabhängige Entwickler, Forscher und Startups, die KI-Produkte entwickeln, bedeutet dies Zugang zu Produktions-Inferenzinfrastruktur ohne Kapitaleinsatz für Hardware-Kauf oder wiederkehrende Kosten für teure Cloud-GPU-Instanzen. Sie mieten Kapazität bei Bedarf, führen Experimente durch oder bedienen Traffic und geben den Knoten frei, wenn fertig. Die Unified Memory Architektur stellt sicher, dass Ihr Euro mehr verarbeitete Tokens pro Stunde kauft.
Datenschutz und Compliance-Überlegungen
Für Unternehmen, die DSGVO-Konformität einhalten müssen, bietet die VPSMAC-Infrastruktur Bare-Metal-Knoten in geografisch definierten Rechenzentrumsstandorten. Im Gegensatz zu Multi-Tenant-Cloud-GPU-Diensten, bei denen Daten durch gemeinsame Speicherhierarchien fließen können, isoliert Unified Memory auf dedizierter Hardware Ihre Inferenz-Workloads vollständig. Modellgewichte und Eingabedaten verlassen niemals den physischen Speicher des gemieteten Knotens; es gibt keine Hypervisor-Schicht oder gemeinsame VRAM-Pools.
Für Anwendungsfälle, die strenge Datenlokalisierung erfordern (z.B. medizinische KI-Modelle in EU-Rechenzentren), ermöglicht VPSMAC die Auswahl spezifischer Knotenstandorte und garantiert, dass Speicher physisch innerhalb der Jurisdiktion bleibt. Dies vereinfacht Compliance-Audits im Vergleich zu virtualisierten Umgebungen, bei denen Datenresidenz durch VM-Migration oder gemeinsame Speicher-Backend-Systeme unklar werden kann.
Fazit: Unified Memory als Wettbewerbsvorteil
Apples Unified Memory Architektur ist kein Marketing-Slogan. Es ist eine fundamentale Verschiebung in der Interaktion von Speicher und Rechenleistung mit messbaren Vorteilen für speichergebundene Workloads wie KI-Inferenz. Die 64GB-Konfigurationen von M4 Pro und M4 Max liefern überlegene Kosteneffizienz für Modelle bis zu 70B Parametern durch Eliminierung von PCIe-Engpässen, Reduktion des Stromverbrauchs und Ermöglichung einfacherer Software-Stacks.
Für Produktions-Deployments, bei denen Latenz, Kosten pro Token und betriebliche Einfachheit wichtig sind, sind 64GB Macs derzeit die effizienteste Option in ihrer Klasse. Da Modellgrößen weiter wachsen und Inferenz zur dominanten KI-Workload wird, wird Unified Memory wahrscheinlich zu einer Wettbewerbsanforderung statt zu einem Nischenvorteil.