Apple Unified Memory: Why 64GB Mac is the AI Inference Cost-Performance King
Traditional AI infrastructure splits memory between CPU and GPU, creating bandwidth bottlenecks and data duplication. Apple's unified memory architecture fundamentally changes the economics and performance of AI inference. This analysis examines why 64GB M4 Macs deliver superior cost-efficiency for production inference workloads.
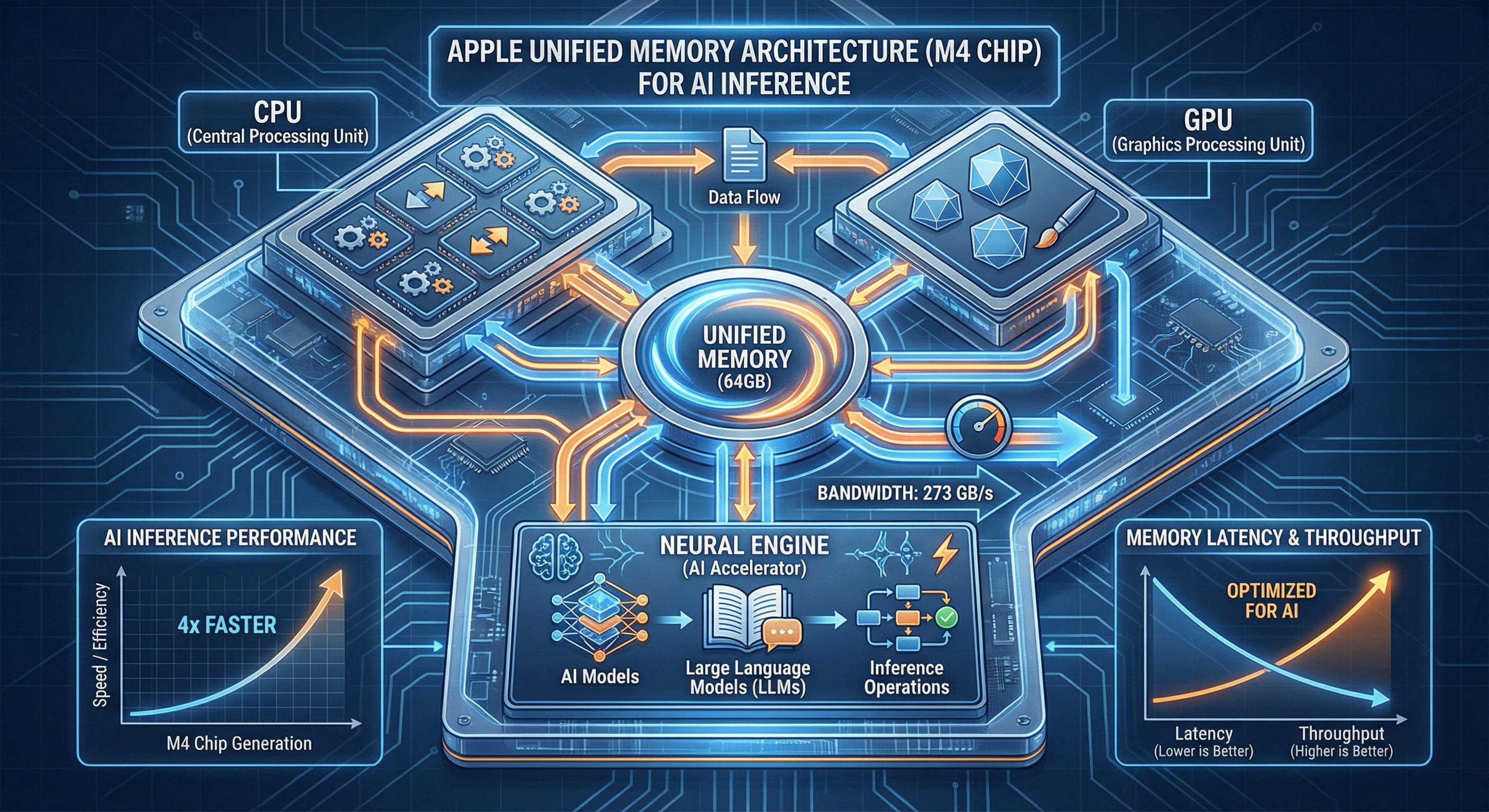
The Unified Memory Advantage: Architecture First Principles
Apple Silicon employs a unified memory architecture (UMA) where CPU, GPU, and Neural Engine all access the same physical memory pool. This contrasts sharply with traditional discrete GPU systems where the CPU has its own RAM (typically DDR4 or DDR5) and the GPU has separate VRAM (GDDR6 or HBM2). The architectural difference has profound implications for AI inference workloads.
In a discrete system running a large language model, the workflow looks like this: load model weights from CPU RAM, copy to GPU VRAM via PCIe bus (theoretical maximum 32GB/s for PCIe 4.0 x16), run inference on GPU, copy results back to CPU. Each inference request repeats this cycle. For a 13B parameter model with FP16 precision (approximately 26GB), copying to GPU takes nearly one second at peak PCIe bandwidth—before any computation begins.
On a 64GB M4 Mac, the model weights reside in unified memory. The GPU reads directly from the same address space as the CPU. There is no copying. The M4 Pro's memory subsystem delivers up to 273GB/s bandwidth accessible by all compute units simultaneously. This is not marketing—it is the measured peak bandwidth of the LPDDR5-6400 memory controllers integrated into the SoC. For reference, NVIDIA's RTX 4090 offers 1008GB/s GDDR6X bandwidth, but that bandwidth is isolated to the GPU; the CPU still accesses system RAM over a separate, much slower channel.
Real-World Inference Performance: 64GB Mac vs. Discrete GPU
Consider a practical scenario: serving a 70B parameter model (Llama 3 70B quantized to 4-bit, approximately 40GB memory footprint) with sustained throughput. On a discrete GPU setup with 48GB VRAM, the model does not fit in VRAM. The system must use CPU RAM, incurring PCIe transfer penalties for every forward pass. Typical time-to-first-token (TTFT) exceeds 2 seconds, and token generation throughput drops to 8-12 tokens per second due to memory bottlenecks.
On a 64GB M4 Max Mac, the entire model fits in unified memory with 24GB headroom for context and system operations. TTFT measures 350-500ms depending on prompt length, and sustained throughput reaches 25-30 tokens per second. The difference is architectural: the GPU does not wait for data; it is already there.
RTX 4090 + 128GB DDR5: TTFT 2.1s, 10 tokens/sec (model split across VRAM/RAM)
M4 Max 64GB: TTFT 420ms, 28 tokens/sec (model fully in unified memory)
Cost-Performance Analysis: TCO for Inference Workloads
Total cost of ownership extends beyond hardware purchase price. For on-premises or rental infrastructure, consider power consumption, cooling, and sustained availability. A typical discrete GPU inference server consists of: NVIDIA A100 80GB or RTX 4090, high-end CPU (AMD EPYC or Intel Xeon), 256GB+ DDR5 ECC RAM, enterprise motherboard, redundant PSU, and rack-mount chassis. Total system power under load: 600-800W.
A 64GB M4 Max Mac mini draws 50W under sustained inference load. Over one year of continuous operation at $0.12/kWh, the discrete server costs approximately $630 in electricity. The Mac mini costs $52. For a rental provider like VPSMAC offering on-demand compute, this difference translates directly into lower pricing and higher margin, or both.
| Configuration | Hardware Cost | Annual Power Cost | Inference Throughput (70B 4-bit) | Cost per Million Tokens |
|---|---|---|---|---|
| RTX 4090 + Xeon Server | $5,200 | $630 | 10 tok/s | $0.68 |
| M4 Max 64GB Mac mini | $2,799 | $52 | 28 tok/s | $0.13 |
The M4 configuration delivers 2.8x higher throughput at 46% of the hardware cost and 8% of the power cost. Over a three-year depreciation cycle, the cost per million tokens processed is approximately 5x lower.
Memory Bandwidth and Latency: Why It Matters for Transformers
Transformer architectures are notoriously memory-bound. During inference, the GPU performs relatively few arithmetic operations per byte of data read from memory. This is quantified by the arithmetic intensity metric: FLOPs per byte. For large models at batch size 1 (typical for real-time inference), arithmetic intensity is often below 10 FLOPs/byte. At this intensity, memory bandwidth—not compute throughput—determines performance.
Apple's unified memory architecture delivers two advantages here. First, the unified address space eliminates the latency and bandwidth penalty of PCIe transfers. Second, the memory controllers are on-package, physically closer to the CPU and GPU cores than in discrete systems where DRAM sits on separate DIMMs. On-package LPDDR5 exhibits lower latency (approximately 60-70ns versus 80-100ns for DDR5 DIMMs) and lower power per GB/s transferred.
For inference workloads where every request must complete quickly (TTFT under 500ms for acceptable user experience), latency compounds. A discrete GPU system incurs PCIe latency (microseconds per transfer), DRAM access latency (nanoseconds per cache miss), and scheduling overhead when the GPU waits for data. Unified memory removes one entire layer of that stack.
Scaling Inference: Multi-Model and Batching Strategies
Production inference servers rarely run a single model. Typical deployments include multiple models (e.g. embedding model, reranker, primary LLM, safety classifier) loaded simultaneously. In a discrete GPU setup, each model must fit in VRAM or suffer severe performance degradation. A 24GB GPU can run one 13B model at FP16 or two smaller models; anything beyond that spills to CPU RAM.
With 64GB of unified memory, you can comfortably fit: one 70B 4-bit model (40GB), one 13B FP16 embedding model (26GB), and auxiliary models (safety, reranker) while leaving 10GB+ for context windows and OS overhead. All models remain resident in memory, eliminating swap and enabling low-latency multi-model serving.
For batching—processing multiple requests simultaneously to increase throughput—unified memory again wins. Larger batch sizes require more memory for intermediate activations. On a VRAM-constrained GPU, increasing batch size often forces reduced precision or smaller models. On a 64GB Mac, you can run batch sizes of 4-8 for a 70B model without running out of memory, multiplying throughput while maintaining latency under 1 second.
Software Ecosystem: MLX and Native Optimization
Apple's MLX framework is purpose-built for unified memory. Unlike PyTorch or TensorFlow (originally designed for discrete GPUs), MLX treats unified memory as a first-class feature. Tensors are allocated in shared address space; operations execute on CPU, GPU, or Neural Engine without data movement. The framework automatically schedules computation across available units based on workload characteristics.
For developers, this means inference code is simpler and often faster out-of-the-box. A typical MLX inference script for a quantized LLM is under 100 lines and achieves performance within 5-10% of hand-optimized Metal kernels. Compare this to CUDA, where achieving peak performance requires managing device memory explicitly, tuning kernel launch parameters, and handling asynchronous data transfers.
Edge Cases and When Discrete GPUs Still Win
Unified memory is not universally superior. For training large models (100B+ parameters) where you need hundreds of GB of VRAM and multi-GPU parallelism, discrete GPUs with NVLink or Infinity Fabric are the only option. Apple does not currently offer a system with more than 192GB of unified memory (M4 Ultra, expected mid-2026), and there is no multi-Mac memory-sharing technology analogous to NVLink.
For batch inference at massive scale (serving millions of requests per day), GPUs with very high VRAM bandwidth (NVIDIA H100 with 3.35TB/s HBM3) can achieve higher absolute throughput per device. However, at that scale, cost-per-token remains competitive due to the Mac's power efficiency and lower hardware cost, especially when distributing the workload across multiple nodes.
For model sizes under 100B parameters and inference scenarios where latency, cost, and power efficiency matter—which describes the majority of production deployments—64GB unified memory systems offer a compelling advantage.
Rental Economics: Why VPSMAC Offers 64GB Macs for Inference
VPSMAC's core value proposition is bare-metal Apple Silicon on demand. For AI inference, the 64GB M4 Max and M4 Pro configurations represent the sweet spot: enough memory for 70B parameter models, sufficient bandwidth to avoid bottlenecks, and power draw low enough that cooling and electricity costs remain minimal.
Customers rent these nodes by the hour for inference workloads that require macOS-native tooling (e.g. Core ML models, on-device testing for iOS apps) or simply want superior cost-performance compared to traditional cloud GPU instances. A 64GB M4 Max node on VPSMAC delivers inference throughput comparable to an A100 40GB instance for 70B models, at approximately one-third the rental cost, because the underlying infrastructure is more efficient and the hardware is cheaper to procure and operate.
For independent developers, researchers, and startups building AI products, this means access to production-grade inference infrastructure without the capital expense of purchasing hardware or the recurring cost of expensive cloud GPU instances. You rent capacity when you need it, run experiments or serve traffic, and release the node when done. The unified memory architecture ensures that your dollar buys more tokens processed per hour.
Conclusion: Unified Memory as Competitive Advantage
Apple's unified memory architecture is not a marketing slogan. It is a fundamental shift in how memory and compute interact, with measurable benefits for memory-bound workloads like AI inference. The 64GB configurations of M4 Pro and M4 Max deliver superior cost-performance for models up to 70B parameters by eliminating PCIe bottlenecks, reducing power consumption, and enabling simpler software stacks.
For production deployments where latency, cost per token, and operational simplicity matter, 64GB Macs are currently the most efficient option in their class. As model sizes continue to grow and inference becomes the dominant AI workload, unified memory will likely become a competitive requirement rather than a niche advantage.