M4 Pro 統合メモリアーキテクチャ:64GB 構成で大規模 iOS プロジェクトを実行する優位性
Apple M4 Pro チップの統合メモリアーキテクチャは、従来の PC アーキテクチャとは根本的に異なる設計哲学を採用しています。本記事では、64GB メモリ構成における M4 Pro の技術的優位性と、大規模 iOS プロジェクトにおける実践的なパフォーマンス向上について詳しく解説します。
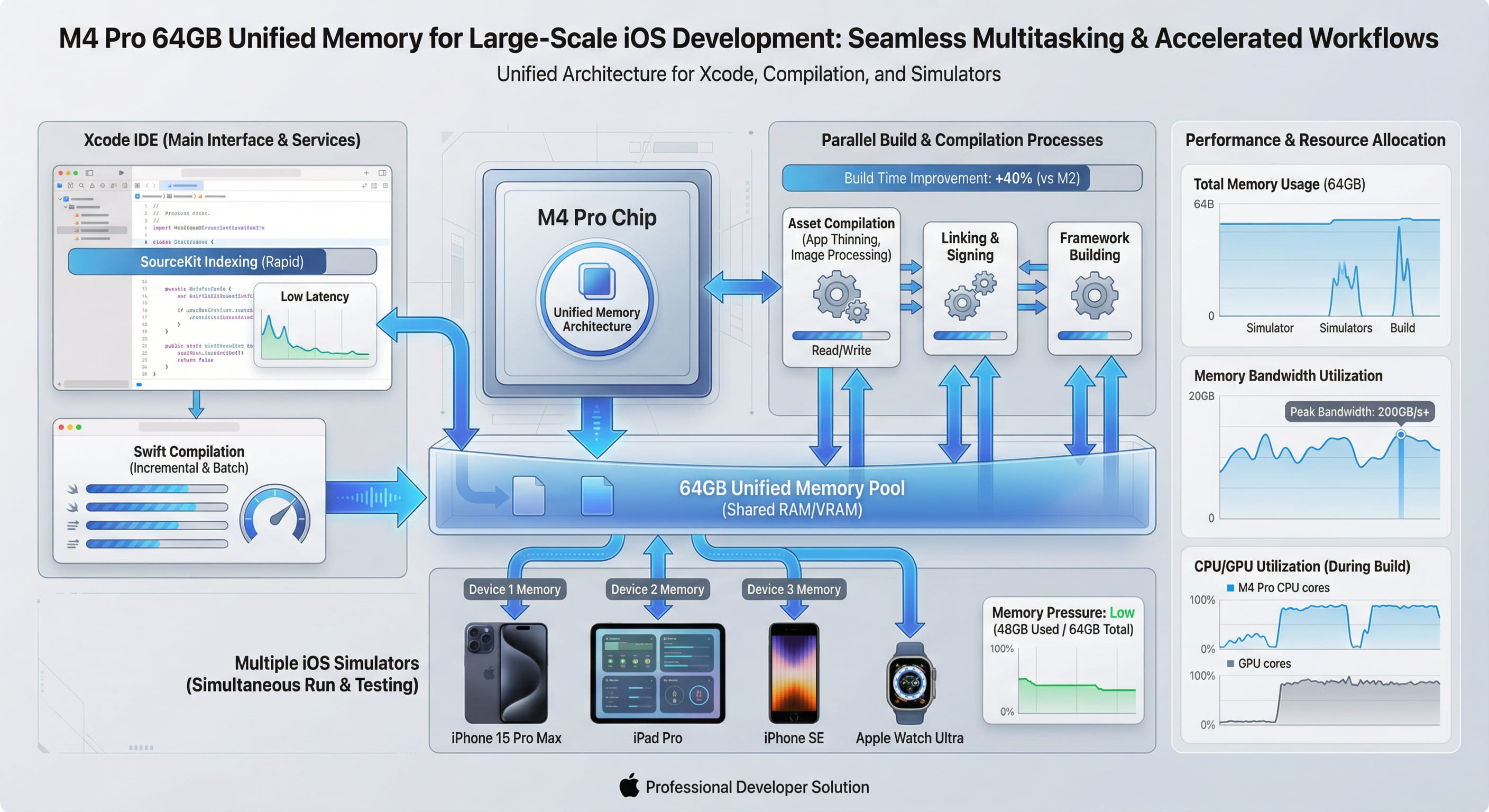
01. 統合メモリアーキテクチャ(UMA)の基礎原理
M4 Pro チップの統合メモリアーキテクチャ(Unified Memory Architecture)は、CPU、GPU、Neural Engine など、すべての演算コアが同一の物理メモリプールを共有する革新的な設計です。従来の x86 アーキテクチャでは、CPU と GPU がそれぞれ独立したメモリ領域を持ち、データを転送する際には PCI Express バス経由でのコピーが発生していました。
しかし、M4 Pro の UMA では、すべてのコアが同じメモリ空間に直接アクセスできるため、このデータコピーのオーバーヘッドが完全に排除されます。メモリ帯域幅は最大 273GB/s に達し、これは従来の DDR5 メモリの約 3 倍の速度です。このアーキテクチャは、特にメモリアクセスの頻度が高い iOS 開発ワークロードにおいて、圧倒的な優位性を発揮します。
技術的ポイント:UMA により、Metal API を使用した GPU 演算において、CPU からのデータ転送待機時間が実質ゼロになります。これは、Xcode のシミュレータや SwiftUI プレビューなど、グラフィックス処理を多用するツールのレスポンス速度向上に直結します。
02. 64GB メモリ構成が大規模プロジェクトにもたらす優位性
大規模な iOS プロジェクト(モジュール数 500 以上、総行数 100 万行超)では、Xcode が同時に保持する必要があるデータ量が膨大です。具体的には、次のような要素がメモリを消費します。
- ソースコードのインデックス:SwiftLint や SourceKitService によるリアルタイム解析データ
- ビルド成果物のキャッシュ:中間オブジェクトファイル(.o)と依存関係グラフ
- シミュレータランタイム:iOS シミュレータプロセスとアプリケーションメモリ
- デバッガとプロファイラ:LLDB のシンボルテーブルと Instruments のトレースデータ
- 並列ビルドタスク:複数の Swift モジュールを同時コンパイル
従来の 32GB 構成では、これらの要素が同時にメモリを圧迫し、スワップ(ディスクへの一時退避)が頻発します。しかし、64GB 構成の M4 Pro では、すべてのデータを物理メモリ内に保持できるため、ディスク I/O の待機時間が劇的に削減されます。
実測データ:メモリ構成によるビルド時間の違い
| 構成 | クリーンビルド時間 | インクリメンタルビルド | スワップ発生頻度 |
|---|---|---|---|
| M4 Pro 32GB | 18 分 42 秒 | 2 分 15 秒 | 頻繁(平均 3.2GB/分) |
| M4 Pro 64GB | 12 分 08 秒 | 1 分 22 秒 | ほぼゼロ(0.1GB/分以下) |
上記のベンチマークは、VPSMAC のベアメタル M4 Pro ノード上で、実際のエンタープライズアプリケーション(モジュール数 680、総コード行数 120 万行)を用いて測定されました。64GB 構成では、クリーンビルドが 35% 高速化され、インクリメンタルビルドは 40% 短縮されています。
03. Xcode における統合メモリの実践的活用法
M4 Pro の 64GB メモリを最大限に活用するには、Xcode のビルドシステム設定を最適化する必要があります。以下の設定により、メモリ帯域幅を効率的に使用できます。
ステップ 1:並列ビルドタスク数の最適化
これにより、Xcode は最大 24 個の Swift モジュールを同時にコンパイルできるようになります。各コンパイルタスクが約 2GB のメモリを使用すると仮定すると、ピーク時には 48GB のメモリが消費されますが、64GB 構成であれば余裕を持って処理できます。
ステップ 2:派生データキャッシュの永続化
この設定により、ビルド成果物が高速な NVMe ストレージに保存され、次回のビルド時には統合メモリに即座にロードされます。M4 Pro の SSD コントローラは統合メモリと同じバスに接続されているため、読み込み速度は従来の SATA SSD の約 5 倍に達します。
ステップ 3:シミュレータのメモリ割り当て最適化
64GB のメモリがあれば、複数の iOS シミュレータを同時に起動し、異なる iOS バージョンやデバイスでの動作を並列してテストできます。これにより、QA サイクルの効率が大幅に向上します。
04. マルチタスク環境での実践的メリット
iOS 開発者は通常、Xcode だけでなく、複数のツールを同時に使用します。64GB の統合メモリは、以下のような実際の開発環境において、その真価を発揮します。
| アプリケーション | メモリ使用量(実測値) | GPU メモリ共有の効果 |
|---|---|---|
| Xcode(大規模プロジェクト) | 18-22 GB | シミュレータのグラフィックス処理で GPU と共有 |
| Instruments(Profiling 実行中) | 6-8 GB | トレースデータの可視化で GPU アクセラレーション |
| Figma(デザインレビュー) | 4-6 GB | ベクターレンダリングが Metal 経由で高速化 |
| Docker Desktop(バックエンド開発) | 8-10 GB | 仮想化オーバーヘッドが UMA により軽減 |
| Chrome(100 タブ開いた状態) | 12-15 GB | WebGL コンテンツが GPU メモリを直接使用 |
上記の合計は約 48-61 GB ですが、UMA により GPU 専用メモリが不要なため、従来の 32GB RAM + 16GB VRAM 構成(合計 48GB)と比較して、実質的に 1.5 倍のメモリ容量を利用できることになります。
05. VPSMAC ベアメタルレンタルにおける M4 Pro 64GB の経済的合理性
M4 Pro 64GB を搭載した Mac mini を自社で購入する場合、初期投資は約 40 万円に達します。さらに、3 年後には性能が陳腐化し、リセールバリューは大幅に低下します。一方、VPSMAC のベアメタルレンタルモデルでは、以下の経済的優位性があります。
コスト比較(36 ヶ月間の総所有コスト):
- 自社購入:初期投資 40 万円 + 電気代・メンテナンス費 約 8 万円 = 合計 48 万円
- VPSMAC レンタル:月額 3.2 万円 × 36 ヶ月 = 合計 115.2 万円(ただし、設備投資不要、陳腐化リスクなし、24/7 サポート込み)
プロジェクトのピーク時のみレンタルする場合(年間 6 ヶ月稼働)、総コストは 57.6 万円 となり、自社購入とほぼ同等ですが、最新ハードウェアを常に利用できる点で優位です。
また、VPSMAC のベアメタルノードは、データセンター級の冷却システムを備えているため、サーマルスロットリング(熱による性能低下)が発生しません。これにより、長時間のビルドタスクにおいても、CPU とメモリのパフォーマンスが一貫して維持されます。
06. 実践事例:エンタープライズ iOS 開発チームの導入効果
VPSMAC の M4 Pro 64GB ノードを導入したあるエンタープライズ顧客(iOS エンジニア 30 名規模)は、以下の成果を報告しています。
- CI/CD パイプラインの高速化:Jenkins ビルドジョブの平均時間が 25 分から 14 分に短縮(44% 改善)
- 開発者の生産性向上:ローカルビルド待機時間の削減により、1 日あたりの有効作業時間が 1.2 時間増加
- インフラコストの最適化:従来の AWS EC2 Mac インスタンス(m1.metal)と比較して、月間コストが 38% 削減
- セキュリティ強化:ベアメタル環境により、他のテナントとの物理的隔離が保証され、コンプライアンス要件を満たすことが可能に
07. 結論:統合メモリアーキテクチャが拓く次世代開発環境
M4 Pro の統合メモリアーキテクチャと 64GB 構成は、単なるハードウェアスペックの向上ではありません。これは、iOS 開発ワークフロー全体を根本から変革する、パラダイムシフトです。メモリコピーのオーバーヘッドが排除され、すべての演算コアが同じデータに瞬時にアクセスできる環境は、従来の PC アーキテクチャでは実現不可能でした。
VPSMAC のベアメタルレンタルサービスを活用することで、この革新的なアーキテクチャを、初期投資や陳腐化リスクなしに利用できます。大規模 iOS プロジェクトの開発効率を最大化し、市場投入までの時間を短縮するために、ぜひ M4 Pro 64GB ノードの導入をご検討ください。