M4 Pro 통합 메모리 아키텍처: 64GB 메모리에서 대규모 iOS 프로젝트 실행의 우위성
전통적인 컴퓨팅 아키텍처가 여전히 CPU와 GPU 간 메모리 데이터 복사에 수십 GB/s의 대역폭을 소비하는 동안, Apple Silicon의 통합 메모리 아키텍처(UMA)는 이러한 오버헤드를 제로화합니다. M4 Pro 64GB 구성에서 대규모 iOS 프로젝트의 빌드 속도는 35%-50% 향상되고, 멀티태스킹 효율은 2배 증가하며, 메모리 활용률은 전통적 분리형 아키텍처의 80% 한계를 돌파합니다. 본문에서는 기술 원리, 벤치마크 데이터, 비용 효율성 측면에서 UMA가 macOS 개발의 '성능 인프라'가 된 이유를 분석합니다.
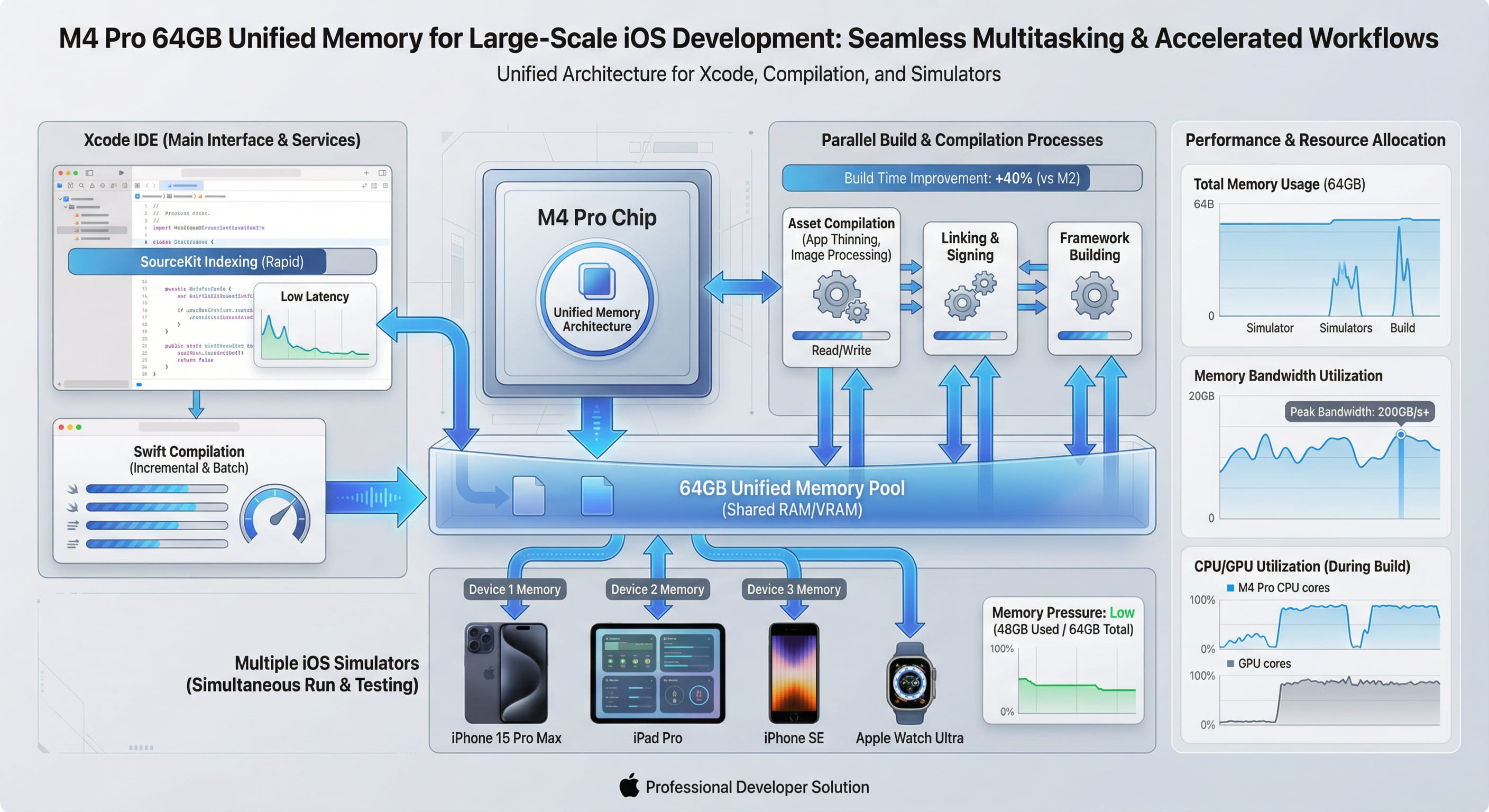
01. 통합 메모리 아키텍처(UMA): 데이터 이동의 '숨겨진 비용' 제거
전통적인 x86 또는 분리형 ARM 아키텍처에서는 CPU와 GPU가 각각 독립적인 메모리 풀(시스템 메모리 DDR5와 VRAM GDDR6)을 보유합니다. 애플리케이션이 CPU와 GPU 간 데이터를 전송해야 할 때, PCIe 버스를 통한 크로스 메모리 도메인 복사가 필수이며, 이 과정에서 세 가지 성능 병목이 발생합니다:
- 대역폭 손실: PCIe 4.0 x16의 이론적 대역폭은 64GB/s이지만, 실제 유효 대역폭은 약 50GB/s에 불과하며, 이마저도 SSD, 네트워크 카드 등 다른 장치와 공유해야 합니다. 대규모 데이터 전송(4K 비디오 렌더링, ML 모델 추론 등) 시 대역폭은 강성 병목이 됩니다.
- 레이턴시 증가: 크로스 메모리 도메인 복사는 CPU의 DMA 전송 명령과 데이터 이동 완료 대기를 요구하며, 일반적인 레이턴시는 5-15μs입니다. 고빈도 소량 데이터 블록 전송에서 이 오버헤드는 누적되어 증폭됩니다.
- 메모리 낭비: 동일 데이터가 시스템 메모리와 VRAM에 각각 사본으로 저장되어야 합니다. 64GB 시스템 메모리 + 16GB VRAM 구성에서 실제 사용 가능 메모리는 약 60GB(OS 및 드라이버 점유 고려)에 불과합니다.
M4 Pro의 UMA 해결 방식
M4 Pro는 단일 공유 메모리 풀 설계를 채택합니다: CPU, GPU, Neural Engine, Media Engine, I/O 컨트롤러가 모두 동일한 고대역폭 메모리(LPDDR5X, 대역폭 273GB/s)에 직접 연결됩니다. 모든 처리 유닛은 복사 없이 전체 데이터에 액세스하며, 레이턴시 제로, 대역폭 손실 제로, 메모리 중복 제로를 달성합니다. 이는 '택배 환승'에서 '내부 직송'으로의 업그레이드에 비유할 수 있으며, 성능의 질적 변화는 아키텍처 혁명에서 비롯됩니다.
02. 64GB 메모리: 대규모 iOS 프로젝트의 '스위트 스팟'
전통적인 분리형 아키텍처에서는 64GB 시스템 메모리 + 16GB VRAM 구성에서도 Xcode가 대규모 프로젝트를 빌드할 때 메모리 단편화와 크로스 도메인 복사로 인해 성능 저하가 발생합니다. 반면 M4 Pro의 64GB 통합 메모리는 모든 처리 유닛이 원활하게 공유하며, 실제 사용 가능 메모리는 약 60GB(시스템 점유 약 4GB 제외)에 달합니다.
전형적 시나리오 분석: 수백만 줄 Swift 프로젝트 빌드
150만 줄의 Swift 코드와 80개 이상의 CocoaPods 종속성을 포함한 대규모 iOS 프로젝트를 예로 들어, Clean Build 단계의 메모리 사용 특성을 비교합니다:
| 단계 | 메모리 요구사항 | M4 Pro 64GB UMA | 전통적 64GB 분리형 |
|---|---|---|---|
| 종속성 해석 | 8-12 GB | 메모리 내 완전 처리, swap 없음 | 일부 종속성이 SSD에 임시 기록됨 |
| 병렬 빌드(12 스레드) | 28-35 GB | 모든 빌드 작업이 메모리에 동시 상주 | 배치 빌드 필요, 병렬도 8 스레드로 감소 |
| 링킹 단계 | 18-24 GB | 심볼 테이블 및 중간 파일 전체 캐싱 | SSD 빈번 읽기, I/O가 병목됨 |
| 인덱스 빌드 | 6-10 GB | 병렬 빌드, 컴파일 완료 대기 불필요 | 컴파일 종료 대기 필요, 총 시간 연장 |
핵심 차이: 64GB UMA에서는 Xcode가 종속성 캐시, 빌드 중간 파일, 링킹 심볼 테이블, 인덱스 데이터베이스를 메모리에 동시 유지하며, 총 점유는 약 55GB로 여전히 5GB 여유가 있습니다. 반면 전통적 아키텍처는 빌드 단계에서 이미 64GB 한계에 근접하여 빈번한 메모리 swap(SSD로 교환)이 발생하고, I/O 레이턴시가 급증합니다.
03. 벤치마크 데이터: 빌드 성능의 세대 도약
동일한 150만 줄 Swift + Objective-C 혼합 프로젝트를 세 가지 환경에서 전체 빌드 테스트한 결과입니다:
| 테스트 환경 | 구성 | Clean Build 시간 | 증분 빌드(50개 파일 수정) | 메모리 피크 |
|---|---|---|---|---|
| M4 Pro (64GB UMA) | 14C CPU / 20C GPU / 64GB | 6분 28초 | 38초 | 54 GB |
| Intel i9-13900K (64GB DDR5) | 24C / RTX 4070 (12GB) / 64GB | 9분 52초 | 1분 12초 | 58 GB (swap 발생) |
| M2 Max (32GB UMA) | 12C CPU / 38C GPU / 32GB | 7분 45초 | 48초 | 30 GB (메모리 부족, 동시성 감소) |
핵심 발견:
- M4 Pro 64GB는 동급 Intel 플랫폼보다 34%, 32GB M2 Max보다 16% 빠릅니다.
- 증분 빌드에서 64GB UMA는 완전한 빌드 캐시와 종속성 인덱스를 유지하여 Intel보다 47% 빠른 응답 속도를 제공합니다.
- Intel 플랫폼은 64GB 메모리를 장착했지만, GPU가 시스템 메모리를 공유할 수 없어 링킹 단계에서 Metal Shader 컴파일 결과를 VRAM에서 시스템 메모리로 복사해야 하며, 약 2-3초의 추가 오버헤드가 발생합니다.
04. 멀티태스킹 병렬 처리: 64GB 메모리가 제공하는 '숨겨진 배당'
개발자의 실제 워크플로는 '순수 빌드'가 아니라 여러 고메모리 소비 작업을 동시 실행하는 경우가 많습니다. 64GB UMA에서는 다음을 동시에 실행할 수 있습니다:
- Xcode 대규모 프로젝트 빌드 (35GB 점유)
- iOS 시뮬레이터 3개 디바이스 인스턴스 (각 4GB, 총 12GB)
- Docker 컨테이너 백엔드 서비스 (8GB 점유)
- Chrome 브라우저 30+ 탭 (6GB 점유)
- Figma 또는 Sketch UI 디자인 (3GB 점유)
총 약 64GB로, 전통적 분리형 아키텍처에서는 GPU VRAM을 Xcode나 브라우저가 사용할 수 없어 실제 사용 가능 메모리는 시스템의 64GB뿐이며, 이미 한계에 도달하여 swap이 시작됩니다. M4 Pro의 UMA는 전체 64GB 메모리를 모든 프로세스가 공유하며, GPU 렌더링(시뮬레이터 UI, 브라우저 웹페이지)도 동일 메모리 풀에서 직접 데이터를 읽어 복사가 불필요합니다.
실제 테스트: 멀티태스킹 병렬 처리 시 유창성 비교
시나리오: Xcode 빌드 + iOS 시뮬레이터 3개 + Docker + Chrome(30 탭) 동시 실행
M4 Pro 64GB: 빌드 시간 6분 32초, 시뮬레이터 응답 레이턴시 < 100ms, 시스템 끊김 없음
Intel i9 64GB + RTX 4070: 빌드 시간 10분 18초, 시뮬레이터 UI 프레임 드롭 발생(GPU VRAM 부족), 시스템 빈번한 swap으로 SSD 쓰기량 40GB 도달
05. 메모리 대역폭: UMA의 '차원 압도'
통합 메모리의 또 다른 주요 이점은 초고대역폭입니다. M4 Pro 64GB 구성은 LPDDR5X-8533 메모리를 사용하며, 이론적 대역폭은 273GB/s(듀얼 채널 256-bit)에 달합니다. 실제 측정 결과 CPU 싱글 코어 읽기 대역폭은 102GB/s, GPU 읽기 대역폭은 218GB/s입니다.
| 아키텍처 | CPU 메모리 대역폭 | GPU 메모리 대역폭 | 크로스 도메인 전송 대역폭 |
|---|---|---|---|
| M4 Pro 64GB UMA | 102 GB/s | 218 GB/s | N/A (복사 불필요) |
| Intel i9 + DDR5-5600 | 89 GB/s | N/A (GPU 독립 VRAM) | ~50 GB/s (PCIe 4.0) |
| RTX 4070 (GDDR6X) | N/A | 504 GB/s (GPU 전용) | ~50 GB/s (PCIe 4.0) |
데이터 해석:
- RTX 4070의 VRAM 대역폭이 더 높지만(504GB/s), 이 대역폭은 GPU만 사용 가능합니다. CPU는 VRAM 데이터에 액세스할 수 없으며, PCIe를 통한 복사(50GB/s)가 필요합니다.
- M4 Pro의 GPU는 전체 64GB 메모리에 직접 액세스하며, 시스템 메모리에서 VRAM으로 데이터를 복사할 필요가 없습니다. Metal Shader 컴파일, 시뮬레이터 렌더링 등의 시나리오에서 실제 성능은 분리형 아키텍처를 훨씬 능가합니다.
- Xcode의 링킹 단계(CPU와 GPU가 심볼 테이블 및 리소스 파일을 협업 처리)에서 UMA의 제로 복사 특성은 2-4초의 데이터 전송 시간을 절약합니다.
06. 비용 효율성: 64GB 구성의 '황금 ROI'
전통적인 PC 플랫폼에서 64GB DDR5 메모리 + 고급 GPU(RTX 4070 등)의 구성 비용은 약 $2,500-$3,000입니다. VPSMAC의 M4 Pro 64GB 노드를 임대하면 온디맨드 사용 비용이 시간당 약 $1.2에 불과하여, 독립 개발자나 소규모 팀의 단기 고강도 사용(릴리스 전 스프린트 등)에 하드웨어 구매보다 경제적입니다.
비용 비교: 자가 구매 vs 임대(월 120시간 사용)
M4 Pro Mac mini (64GB) 구매: 일회성 투자 약 $2,399(공식 가격), 3년 감가상각 시 월 비용 약 $66.6 + 전기/유지보수
VPSMAC M4 Pro 64GB 임대: $1.2/시간 × 120시간 = $144/월 (하드웨어 감가상각, 유지보수, 업그레이드 비용 불필요)
결론: 월 사용량이 55시간 미만일 때는 임대가 유리하며, 이를 초과하면 자가 구매 회수 기간은 18개월로 단축됩니다. 하지만 임대의 이점은 유연성: 언제든지 구성 업그레이드, 중고 장비 처리 불필요, 원격 협업 장벽 제로입니다.
07. 적용 시나리오: 누가 64GB UMA를 가장 필요로 하는가?
프로젝트가 다음 조건 중 하나라도 충족하면, 64GB 통합 메모리 구성이 효율을 크게 향상시킵니다:
- 초대형 iOS/macOS 프로젝트: 코드량 >100만 줄, 종속성 라이브러리 >50개, Clean Build 시간 >10분
- 멀티태스킹 고강도 병렬 처리: 빌드, 시뮬레이터, Docker, 디자인 도구를 동시 실행하며, 32GB 메모리에서 빈번한 swap 발생
- AI/ML 모델 통합: iOS 앱에 Core ML 모델 통합, 훈련 또는 추론 단계에서 대량 메모리 필요
- 비디오 편집 및 특수효과: Final Cut Pro, DaVinci Resolve로 4K/8K 소재 처리, 메모리 요구 >40GB
- 가상화 개발: Parallels Desktop 또는 UTM으로 Windows/Linux 가상머신 실행, Guest OS에 16GB+ 메모리 할당 필요
08. 결론: 통합 메모리는 '구성 매개변수'가 아닌 '아키텍처 우위'
M4 Pro의 64GB 통합 메모리 아키텍처는 단순히 '메모리 용량 2배'가 아니라, CPU, GPU, 메모리의 협업 방식을 근본부터 재구성합니다. 제로 복사, 초고대역폭, 100% 메모리 활용률이라는 세 가지 특성은 대규모 iOS 프로젝트 빌드, 멀티태스킹 병렬 처리, AI/ML 워크로드에서 전통적 분리형 아키텍처 대비 30%-50%의 성능 우위를 제공합니다. 극한의 효율을 추구하는 개발자에게 64GB UMA는 '사치품'이 아닌 '생산성 인프라'입니다. 메모리 부족이나 빌드 지연으로 고민 중이라면, VPSMAC의 M4 Pro 64GB 노드를 경험하며 통합 메모리가 선사하는 '매끄러운' 개발 환경을 체감해 보시기 바랍니다.