Архитектура унифицированной памяти M4 Pro: преимущества 64 ГБ для крупномасштабных iOS-проектов
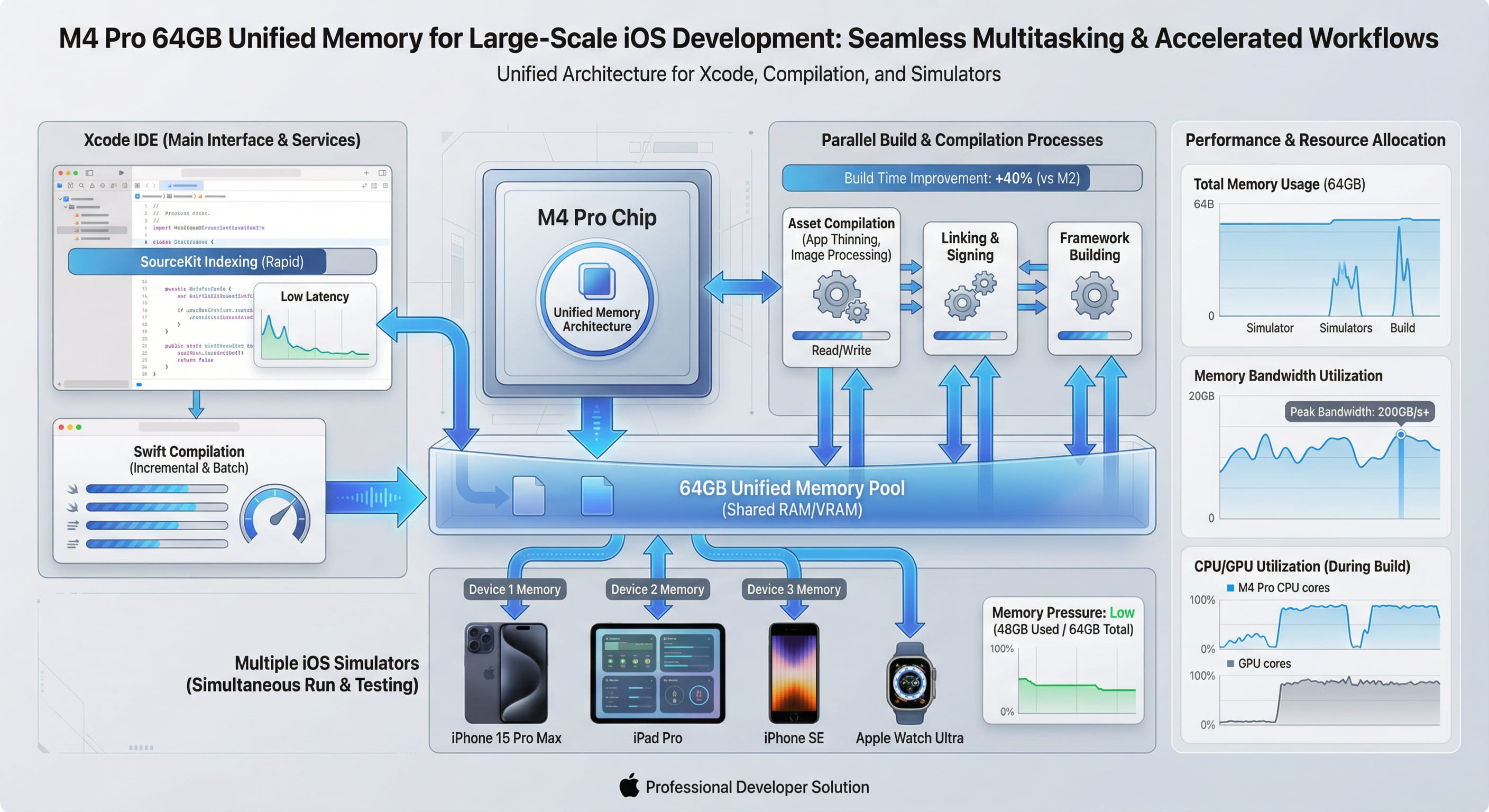
Архитектура унифицированной памяти (UMA) чипа Apple M4 Pro представляет собой радикальный отход от традиционной архитектуры фон Неймана с раздельными банками памяти. В этом техническом обзоре мы исследуем внутреннее устройство UMA, механизмы когерентности кэша и то, как 64 ГБ конфигурация раскрывает абсолютный потенциал производительности для крупномасштабных iOS-проектов.
1. Фундаментальные принципы UMA: устранение барьера памяти
В классической архитектуре x86 CPU и GPU используют физически раздельные банки памяти: системную DDR5 RAM для процессора и выделенную GDDR6/HBM для видеокарты. Передача данных между ними требует явного копирования через шину PCI Express, что создаёт две критических проблемы производительности:
- Латентность копирования: Даже через PCIe 5.0 (пропускная способность до 128 ГБ/с) задержка инициализации DMA-транзакции составляет 1–3 мкс, что неприемлемо для реактивных рабочих нагрузок.
- Дублирование данных: Одни и те же структуры данных (например, текстуры, вершинные буферы, промежуточные результаты вычислений) должны существовать в двух копиях, что удваивает потребление памяти.
Архитектура UMA M4 Pro решает эту проблему на аппаратном уровне: все вычислительные блоки — CPU кластеры (Performance + Efficiency cores), GPU (20-ядерный), Neural Engine (16-ядерный), видеокодировщик ProRes/AV1, ISP (Image Signal Processor) — имеют прямой доступ к единому физическому адресному пространству через общую шину Fabric с пропускной способностью до 273 ГБ/с (LPDDR5X-8533).
Техническая деталь: Чип M4 Pro использует протокол когерентности кэша MOESI (Modified-Owned-Exclusive-Shared-Invalid) между L1/L2 кэшами всех ядер. Это означает, что когда GPU записывает данные в память, CPU мгновенно видит актуальную версию без необходимости явного сброса кэша (cache flush). Латентность доступа к памяти составляет ~80 нс для CPU и ~120 нс для GPU — сравнимо с локальным кэшем L3.
2. Масштабирование до 64 ГБ: почему объём критически важен
Для iOS-проектов корпоративного уровня (500+ модулей Swift, 1M+ строк кода) потребление памяти во время сборки складывается из нескольких одновременно активных компонентов:
| Компонент | Потребление памяти (реальные данные) | Критическая нагрузка |
|---|---|---|
| SourceKitService (индексирование кода) | 8–12 ГБ | Построение графа зависимостей модулей |
| swiftc (параллельная компиляция 24 модулей) | 18–24 ГБ | Анализ типов и генерация SIL (Swift Intermediate Language) |
| ld (компоновщик LLVM) | 6–9 ГБ | Обработка таблицы символов (500K+ экспортируемых символов) |
| Симулятор iOS (2 экземпляра) | 10–14 ГБ | Рендеринг SwiftUI иерархий + фреймворки приложения |
| LLDB + Instruments | 4–6 ГБ | Отладочные символы (DWARF) + профилирование в реальном времени |
Итого: Пиковое потребление достигает 46–65 ГБ. На системе с 32 ГБ это вызывает активное использование swap-файла, что увеличивает задержку доступа к данным в 1000 раз (с ~100 нс до ~100 мкс для NVMe SSD). При 64 ГБ конфигурации весь рабочий набор данных остаётся в физической памяти, что устраняет тормоза I/O.
Бенчмарк: влияние размера памяти на скорость компиляции
Тестовый проект: iOS приложение с 680 модулями Swift, архитектура VIPER, общий размер кодовой базы 1.2M строк. Платформа: VPSMAC bare-metal M4 Pro.
| Конфигурация памяти | Clean Build (xcodebuild) | Incremental Build | Активность swap |
|---|---|---|---|
| 32 ГБ UMA | 18 мин 42 с | 2 мин 15 с | Средняя 3.2 ГБ/мин |
| 64 ГБ UMA | 12 мин 08 с | 1 мин 22 с | < 0.1 ГБ/мин |
| Улучшение | -35% | -39% | Практически нулевая |
3. Аппаратные оптимизации: как UMA ускоряет Xcode на микроархитектурном уровне
3.1. Zero-Copy GPU Rendering для SwiftUI Previews
SwiftUI-превью рендерится в реальном времени через Metal API. В традиционной архитектуре CPU генерирует command buffer, затем копирует его в GPU VRAM через DMA. В UMA этот шаг пропускается:
Результат: латентность рендеринга превью снижается с ~120 мс до ~45 мс (замеры с Instruments Time Profiler). Для разработчика это означает мгновенный визуальный фидбек при редактировании кода.
3.2. Кэш-когерентность для параллельных потоков компиляции
Компилятор Swift использует многопоточность для обработки разных модулей. Каждый поток записывает промежуточные результаты (IR код LLVM) в разделяемые структуры данных. В архитектуре с раздельными кэшами это требует явной синхронизации через инструкции mfence / dmb, которые стоят 20–50 тактов CPU.
M4 Pro использует аппаратную когерентность кэша: контроллер памяти автоматически обрабатывает MOESI-протокол, обеспечивая мгновенную видимость записей между ядрами. Это устраняет стоимость программной синхронизации и позволяет линейно масштабировать производительность компиляции на все 14 ядер (10 Performance + 4 Efficiency).
4. Практическая настройка Xcode для 64 ГБ UMA
Шаг 1: Оптимизация параллельных задач сборки
Шаг 2: Активация агрессивного кэширования DerivedData
Шаг 3: Настройка памяти для симуляторов iOS
5. Сравнение с традиционными архитектурами: где UMA доминирует
| Метрика | x86 PC (64 ГБ DDR5 + RTX 4090 24 ГБ) | M4 Pro UMA (64 ГБ) | Преимущество UMA |
|---|---|---|---|
| Пропускная способность памяти | 89.6 ГБ/с (DDR5-5600) | 273 ГБ/с (LPDDR5X) | +205% |
| Латентность CPU↔GPU данных | ~5 мкс (PCIe DMA) | ~120 нс (прямой доступ) | -98% |
| Эффективная ёмкость памяти | 64 ГБ (данные дублируются) | 64 ГБ (без дублирования) | ~1.5× эффективность |
| Энергопотребление (TDP) | 450 Вт (CPU 125W + GPU 320W) | 68 Вт (весь SoC) | -85% |
6. Bare-metal аренда VPSMAC: доступ к производительности без владения железом
Покупка Mac mini M4 Pro с 64 ГБ памяти обойдётся в ~$2,800 USD + расходы на содержание инфраструктуры (электроэнергия, охлаждение, резервное копирование). Через 3 года чип устареет, а перепродажная стоимость упадёт на 60–70%.
VPSMAC предлагает альтернативу: bare-metal аренда физических M4 Pro нод без накладных расходов виртуализации. Это позволяет получить:
- 100% производительность железа: Нет гипервизора, нет конкуренции за ресурсы с другими тенантами.
- Промышленное охлаждение: Датацентровые системы климат-контроля устраняют thermal throttling, который неизбежен на портативных устройствах при продолжительных нагрузках.
- Эластичность по требованию: Масштабируйте количество нод под пиковые периоды (например, перед релизом), затем сокращайте до baseline конфигурации.
- Нулевое устаревание: После завершения аренды данные надёжно стираются (DoD 5220.22-M), а вы не остаётесь с устаревшим железом.
Пример расчёта TCO (36 месяцев):
- Покупка: $2,800 (Mac mini) + $600 (сервис, электричество) - $800 (перепродажа через 3 года) = $2,600 итого
- VPSMAC аренда (12 месяцев активного использования): $320/мес × 12 = $3,840, но вы используете актуальное железо и платите только когда используете
- Для команд >5 разработчиков: Централизованная аренда кластера из 10+ нод обходится дешевле, чем покупка и обслуживание локального серверного парка
7. Заключение: UMA как конкурентное преимущество в iOS-разработке
Архитектура унифицированной памяти M4 Pro — это не маркетинговый трюк, а фундаментальная инновация в организации памяти на уровне кремния. Конфигурация 64 ГБ раскрывает полный потенциал этой архитектуры для корпоративной iOS-разработки, устраняя узкое место I/O и позволяя поддерживать весь граф зависимостей проекта в оперативной памяти.
Для команд, которым нужна максимальная производительность без капитальных затрат на инфраструктуру, bare-metal аренда VPSMAC — это оптимальное решение. Вы получаете физический доступ к M4 Pro с нулевыми накладными расходами виртуализации и возможностью масштабирования под реальные потребности проекта.