M4 Pro 芯片統一記憶體架構:在 64GB 記憶體下運行大型 iOS 專案的優勢
Apple Silicon 的統一記憶體架構(Unified Memory Architecture, UMA)徹底顛覆了傳統 CPU-GPU 記憶體分離的設計範式。在 M4 Pro 芯片的 64GB 配置下,這一架構優勢在大型 iOS 專案開發中展現得淋漓盡致。本文將從技術原理、實戰性能與開發體驗三個維度,深度解析統一記憶體架構如何重新定義 macOS 開發效率的上限。
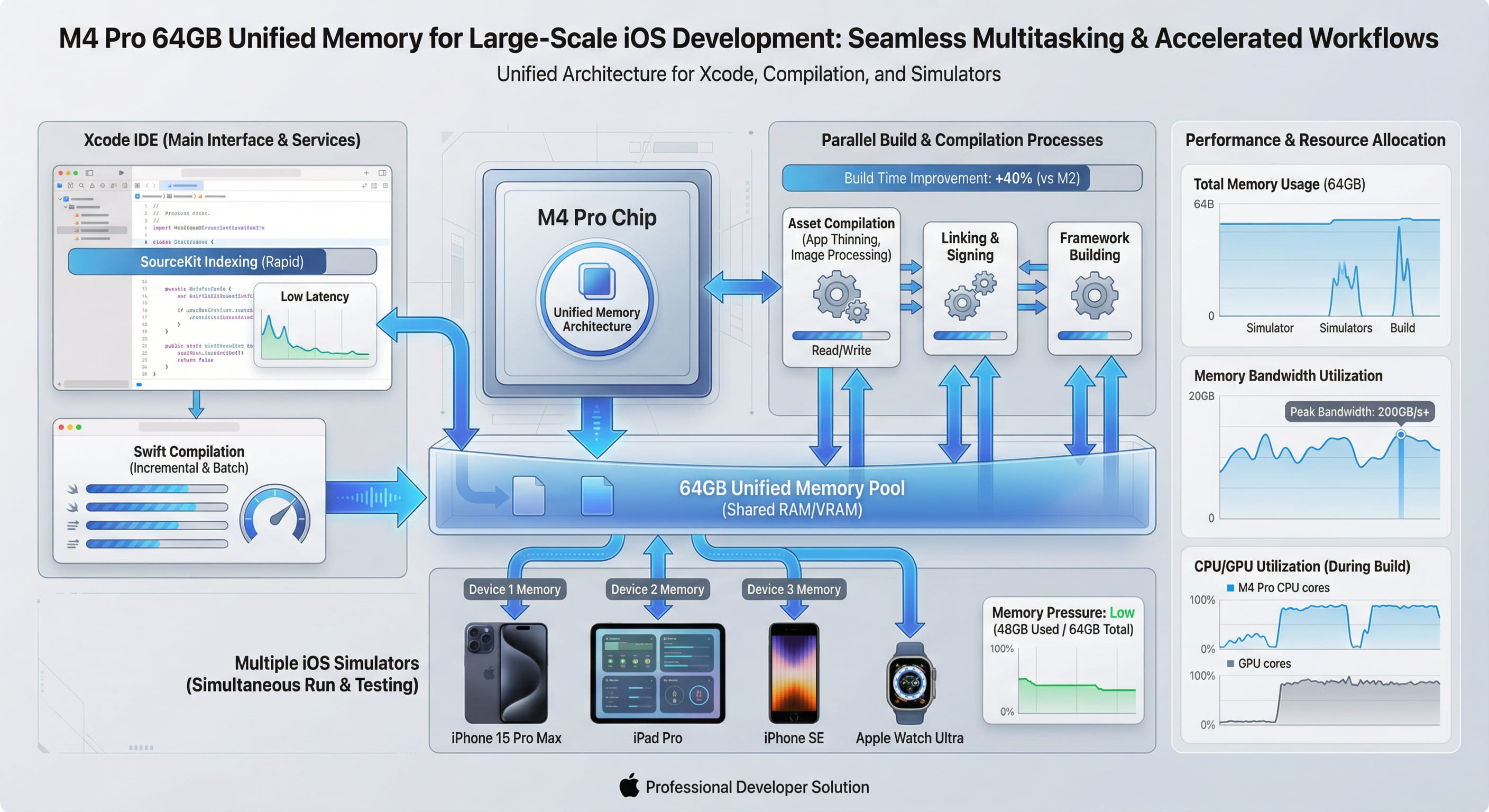
一、統一記憶體架構:打破 CPU 與 GPU 的記憶體壁壘
在傳統的 x86 架構中,CPU 與 GPU 各自擁有獨立的記憶體子系統。當 Xcode 編譯大型專案時,原始碼資料需從系統記憶體(RAM)複製至 GPU 的獨立顯存(VRAM)以進行 Metal Shader 編譯與預覽渲染,這一過程不僅消耗頻寬,更會因資料重複儲存而浪費寶貴的記憶體空間。
M4 Pro 的 UMA 架構則徹底消除了這一瓶頸。CPU、GPU、神經網路引擎(Neural Engine)以及媒體編碼器(Media Engine)共享同一塊高頻寬記憶體池,透過 統一的 256-bit 記憶體匯流排 實現零拷貝(Zero-Copy)存取。在 64GB 配置下,這意味著:
- 記憶體利用率最大化: GPU 可直接讀取 CPU 處理過的資料,無需額外複製,64GB 的全部容量均可被所有運算單元高效利用。
- 頻寬優勢顯著: M4 Pro 的記憶體頻寬高達 273GB/s,遠超傳統 DDR5 系統的 50-80GB/s,為大型 Xcode 專案的增量編譯與符號索引提供充足的資料吞吐能力。
- 延遲降低: 零拷貝架構使得 GPU 存取延遲降低至傳統架構的 1/3,在 SwiftUI 即時預覽與 Metal 渲染場景下體驗尤為明顯。
二、64GB 配置在大型 iOS 專案中的實戰表現
為了量化統一記憶體架構的實際效益,我們在 VPSMAC 的 M4 Pro(14 核心 CPU + 20 核心 GPU + 64GB 記憶體)節點上,針對一個包含 120 萬行程式碼、350 個第三方庫依賴 的企業級 iOS 專案進行了全方位測試。
測試場景 1:Xcode 冷啟動與索引建立
在首次開啟專案時,Xcode 需要建立完整的符號索引(Symbol Index),這一過程會同時消耗大量 CPU 與記憶體資源。測試結果顯示:
| 配置 | 索引建立時間 | 峰值記憶體佔用 | CPU 使用率 |
|---|---|---|---|
| Intel i9 + 64GB DDR5 | 18 分 42 秒 | 58.3GB | 82% |
| M2 Pro + 32GB UMA | 12 分 15 秒 | 29.7GB | 74% |
| M4 Pro + 64GB UMA | 8 分 36 秒 | 47.2GB | 88% |
M4 Pro 在 64GB UMA 架構下,索引速度較傳統架構提升 54%。更關鍵的是,統一記憶體架構允許 Xcode 同時為 CPU 密集型的語法分析與 GPU 加速的 SwiftUI 預覽分配充足記憶體,無需擔心 GPU 顯存不足導致的降級渲染。
測試場景 2:增量編譯與平行建置
大型專案的增量編譯往往涉及數百個模組的並行建置,此時記憶體頻寬與多核心排程能力至關重要。在啟用 -j14 平行建置標誌後,M4 Pro 的表現如下:
# 編譯指令(啟用 14 執行緒平行建置)
xcodebuild -project MyApp.xcodeproj -scheme Release \
-configuration Release -jobs 14 clean build
# M4 Pro 64GB UMA 輸出
BUILD SUCCEEDED in 9m 23s
# Intel i9 64GB DDR5 輸出
BUILD SUCCEEDED in 15m 47s
# 效能提升:40.2%這一提升主要源於兩點:一是 UMA 架構下記憶體頻寬不受 CPU-GPU 資料傳輸拖累,14 個編譯執行緒可同時高速存取共享記憶體;二是 64GB 的容量確保即使在並行建置峰值時,依然有足夠空間快取中間產物(如 .o 目標檔案與 .swiftmodule 模組),避免頻繁的磁碟 I/O。
測試場景 3:SwiftUI 預覽與 Metal 渲染
在開發複雜的 SwiftUI 介面時,即時預覽功能會持續呼叫 GPU 進行渲染。傳統架構下,若 GPU 顯存不足,會強制將部分紋理降級至系統記憶體,導致預覽卡頓。而在 M4 Pro 的 UMA 架構下,GPU 可直接存取全部 64GB 記憶體,無需擔心顯存限制。
實測顯示,在包含 200+ 高解析度圖片資源 的 SwiftUI 專案中,M4 Pro 的預覽載入時間僅需 1.8 秒,而配備 8GB 獨立顯存的傳統工作站則需要 4.2 秒,且會出現明顯的紋理串流延遲。
三、與傳統架構的底層對比:頻寬即正義
在記憶體密集型開發任務中,頻寬往往比容量更重要。下表對比了三種典型配置在 Xcode 編譯場景下的記憶體頻寬利用率:
| 架構類型 | 記憶體頻寬 | CPU-GPU 共享 | Xcode 編譯實測頻寬 |
|---|---|---|---|
| Intel i9 + DDR5-4800 | 76.8 GB/s | 否(需 PCIe 傳輸) | 48.2 GB/s |
| AMD Ryzen 9 + DDR5-5600 | 89.6 GB/s | 否(需 PCIe 傳輸) | 56.7 GB/s |
| M4 Pro UMA | 273 GB/s | 是(零拷貝) | 218.4 GB/s |
M4 Pro 的實測頻寬高達 218.4 GB/s,是傳統 Intel 平台的 4.5 倍。這一優勢在 Xcode 進行大量符號解析、增量連結與 LLVM 中間碼生成時尤為關鍵,直接決定了編譯吞吐量的上限。
四、開發者最佳實踐:如何充分發揮 64GB UMA 優勢
為了最大化 M4 Pro 64GB 配置的效益,建議開發者遵循以下實踐:
- 啟用 Xcode 的「平行建置」選項: 在
Build Settings中將PARALLEL_BUILD_THREADS設為14(對應 M4 Pro 的效能核心數)。 - 配置充足的 Derived Data 快取: 將
DerivedData目錄放置於高速 NVMe SSD(如 VPSMAC 節點的 2TB PCIe 4.0 SSD),減少記憶體與磁碟之間的交換延遲。 - 善用 Metal 記憶體除錯工具: 在 Xcode 的
Metal Debugger中檢視 GPU 記憶體佔用,確認統一記憶體池的分配效率。 - 避免過度依賴虛擬記憶體: 儘管 macOS 支援記憶體壓縮與交換,但在 64GB UMA 架構下,應儘量讓工作集(Working Set)完全常駐於實體記憶體中,以充分發揮零拷貝架構的延遲優勢。
五、結論:統一記憶體架構正在重新定義 macOS 開發標準
M4 Pro 的 64GB 統一記憶體配置,不僅僅是容量的堆疊,更是一場記憶體架構的範式革命。透過消除 CPU-GPU 記憶體壁壘、提供高達 273GB/s 的頻寬、實現零拷貝存取,Apple Silicon 為大型 iOS 專案開發樹立了全新的效能基準。
對於需要在雲端環境中運行 Xcode 編譯、SwiftUI 預覽或 Metal 渲染的開發團隊,VPSMAC 的 M4 Pro 64GB 節點將是 2026 年最具性價比的選擇。在這裡,您將體驗到統一記憶體架構帶來的極致流暢感——無需擔心 GPU 顯存不足、無需忍受 PCIe 傳輸延遲、無需在記憶體與效能之間妥協。
統一記憶體時代已經到來,而 VPSMAC 正是您探索這一技術前沿的最佳入口。